March 2020 Monthly Update
By Daniel Compton
Housekeeping
This is the last update from Oz, thanks Christopher! Tim Pope started work on Fireplace on April 1. We’re currently receiving proposals for our Q2 2019 funding round. This time around, we’re adding two new questions to our application to help us pick projects:
- “Have you been personally impacted by the COVID-19 crisis? How?”
- “Are you part of a group that is affected by systemic bias, particularly in technology? If so, can you elaborate?”
Oz
Oz Updates - Honing in on API updates
Picking up from my latest update, I’ve been reviewing the changes proposed in the last post. Along the way, I cleaned up the API diagram.
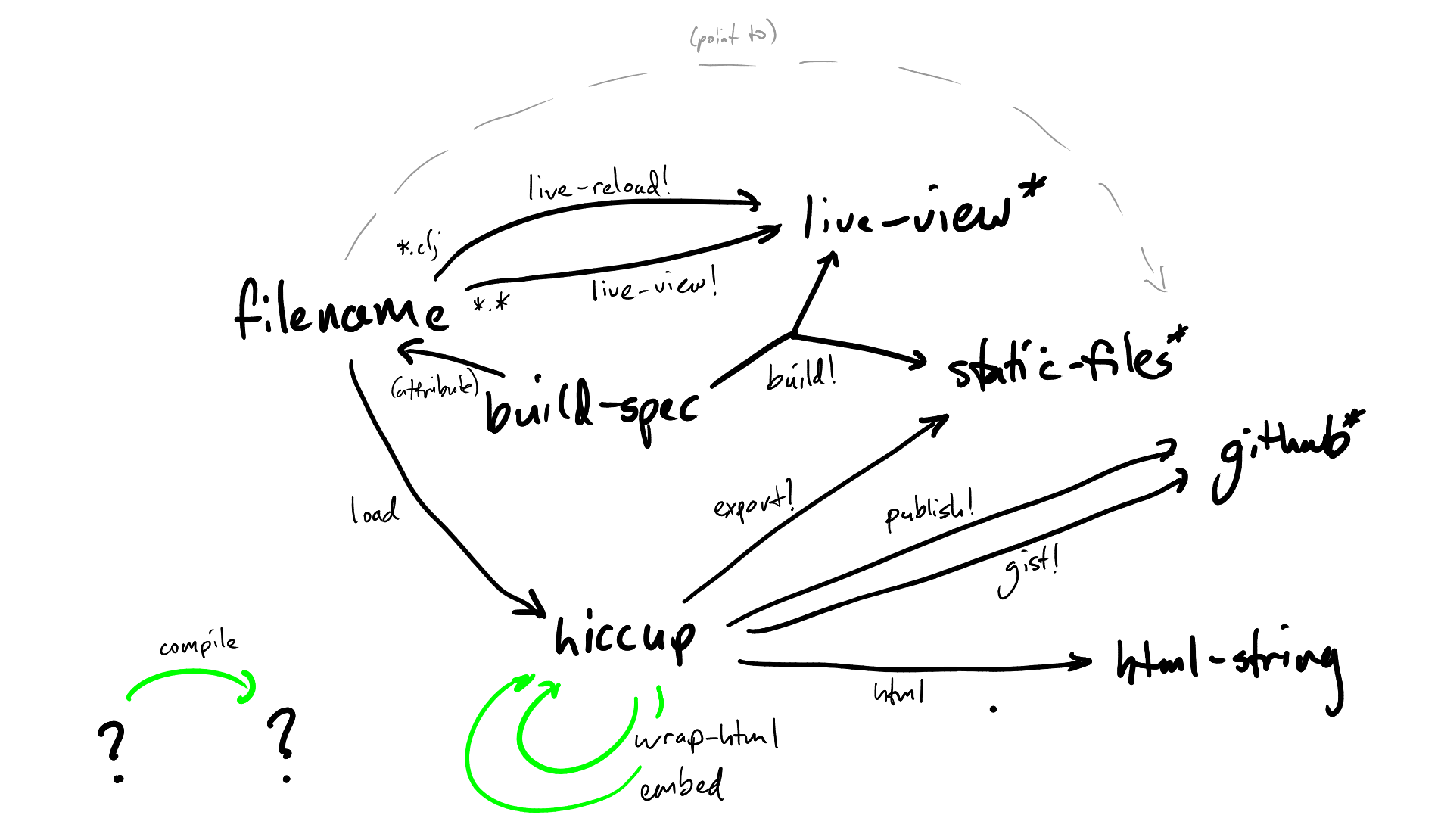{kind=link}
Note that:
- The green arrows represent new API functions.
- Targets with a
*represent side effects. - There’s a bit of double-speak going on with
filenamevsstatic-files*, but the graph made more sense this way.
Specifically regarding the new API functions:
compileaims to be a new general purpose conversion/compilation function, based on multimethods (more on this below).wrap-htmlis for taking a hiccup document and wrapping it in an[:html ...]tag with all of the goodies needed for compiling to html.- This comes with a slew of new options for controlling the styling/details of the output, as relate to headers and such.
embedtakes hiccup which might contain Vega-Lite/Vega visualizations and embeds the corresponding viz blocks as html which can be live rendered.- This will eventually come with options for how you want to embed; as a live interactive viz, a static image, or both (live viz replaces static once ready).
More on compile
I think the biggest of these breakthroughs is the compile function. I’ve had a sense for some time now that the way we think about taking one thing and getting another was in need of some massive overhaul. We already have a html function for rendering hiccup &/or Vega-Lite/Vega as html. And we’re looking at having support for static viz compilation and a pdf mode. With all of that going on, I didn’t want to start tacking on new API function left and right without thinking about the right way to organize it all.
Here’s a map of all the conversions we need to be able to handle:

To handle all of this sanely, I propose a multimethod system where compilers can be registered based on :to & :from entries in an opts map. The default multimethod implementation would first convert the input data to :hiccup, and then convert that hiccup to whatever the intended output format is. This gives us a flexible system where we only have to specify conversions to/from hiccup for any given output type we might want to add in the future, but when appropriate, we can override this when we have a way of implementing it more efficiently.
Note that this all also has to play nice with export!, which is going to get a bit of a makeover in the process, allowing you to export :to a particular format. The default implementation will be to use compile with the appropriate :from and :to settings. However, in cases where we’d just be calling out to the vega-cli, we can override to call out to the CLI directly.
Options
Across the API, I’ve been reviewing all of the options, and adding specs for them. I’m taking the time to do this now to ensure that the overlapping functionality in compile, export!, vega-cli feels internally consistent, and to avoid any conflicts in intended meaning. This is particularly important with a number of functions which expect to be shuttling data back and forth between each other, such as compile and export! as defined above.
Crazy idea
One of the crazier ideas that has popped up though (and one on which I’d like feedback), is that I’d like to make these functions accept options in two different styles:
(export! data filename opts)
(export! data filename & {:as opts})
The story here is this: When I inherited forked Oz (from Vizard), it’s API used the & {:as opts} variant, and not wanting to break the API for folks who wanted to switch, I stuck with this. At the time, the only real function in the API was the view! function. Given that this was primarily intended for REPL usage, I wasn’t too concerned about this.
As Oz grew, I made the decision to stick with the existing pattern, to maintain consistency in the API. However, as more and more of the functionality has come to expand beyond the focus of REPL tooling, this has started to irk me. I like being able to pass option maps as a single argument, as it makes it easier to compose/compute these options and pass in. As mentioned, I didn’t want to make the API inconsistent, and I certainly didn’t want to break any of it.
The thought occurred to me that I could support both options by defining like this
(defn export!
([data filename] (export! data filename {}))
([data filename opts]
( ...))
([data filename opt-k opt-val & {:as more-opts}]
(export! data filename (assoc more-opts opt-k opt-val))))
Having not seen this in the wild much, I kept telling myself it was crazy. But maybe it’s crazy like a fox!
And so, with compile and friends (see above) en route, I’d like some feedback from the community about whether they think this is a good idea or not. With that in mind, I invite you to contribute to this advisory twitter poll!
https://twitter.com/metasoarous/status/1240085028064727040?s=20
Please leave a vote, and if you have any more specific/nuanced thoughts or concerns, please let me know in a comment there! And thank you in advance for the feedback!
Pull requests!
I’ve been very fortunate this last couple of weeks to have a number of pull requests come in. Some of them have been simple README fixes, others fixes for usage with Shadow-CLJS (which I’m considering switching to at some point). Thanks to everyone who has submitted one of these, or even just submitted an issue or comments on an issue letting me know of things that need attention. It’s wonderful to have such a helpful community of users :-)
Conclusion
It may feel like things have been moving slowly, but there’s been a lot of progress in speccing things out, and hammocking my way through some of the core design problems that Oz faces. And with a number of pull requests having made it in the last few weeks, please expect a release soon which captures all of this great work.
Ring
March 1-15
The draft spec has now been updated in response to community feedback, and work on the Ring 2.0 alpha code has begun. The core protocols for requests and responses have been finished, and work is nearly complete on the servlet interop functions and Jetty adapter. Once the tests are all working, the 2.0 branch will be updated.
This leaves websocket support and middleware updates as the next
significant tasks before the first alpha release. Utility namespaces
such as ring.util.request and ring.util.response namespaces will
likely remain Ring 1.0 only, with some of their functionality being
added to the ring.request and ring.response namespaces. I’d like
to keep the new namespaces as lightweight as possible, as they’ll be
required for anyone using the new protocols.
March 16-31
The servlet interop functions and Jetty adapter have been updated to support the Ring 2.0 request and response formats. After further comments by the community, I’ve decided to focus a little more on benchmarking performance for this release, and having looked over the code I’m cautiously optimistic that we can make things a little more efficient despite the new features.
I’ve also decided to test an approach where the default is to support both Ring 1 and 2 keys in the request map, allowing Ring 1 routes and Ring 2 routes to be present in the same application. For those applications that don’t need either Ring 1 or Ring 2 support, there will be an adapter option to force adherence to one version only.
Calva
March 1-15
Debugger
Breakpoints are now found correctly when using the #dbg and #break reader tags, as seen in Cider’s debugging docs. I’ve made the functionality around the “continue” debug option more stable and polished. Some work was done by Peter to improve the token cursor navigation and highlighting concerning reader tags as well, and that has been merged into the debugger branch and helped with finding the location of breakpoints in the editor.
I’ve added the feature for evaluations during debug sessions in the context of the debugger. So, for instance, if execution is stopped on a breakpoint, the user can evaluate expressions in the local context, and this can be done in the editor or the REPL window, just as normal evaluations work. When a debug session starts, the REPL window prompt will change to <<debug-mode>>=> to indicate that evaluations will be made in the local context. This gives us the multi-line editing, paredit, and syntax highlighting features of the REPL window to use for debug evaluations, instead of using VS Code’s Debug Console.
Maps and collections are not structured yet in the “Variables” section of the side pane that shows the value of local variables while stopped at breakpoints, but the user can use the above-mentioned features to evaluate data in the editor or in the REPL window, and the pretty printing setting is respected in these cases.
My plans next are to write some tests around this initial core functionality, then write documentation, then do an initial release. This way we can start to get some feedback on the core of the debugger and fix any issues that might arise, plus make sure we’re heading in the right direction.
Configuration of Formatting
Calva’s formatter can now be configured to support different formatting policies - a big thanks to nbardiuk. This is something users have been asking for, and we’re excited to offer it now! See this post for more information.
Other Improvements
We are experimenting with leveraging clojure-lsp for static analysis, and have also added more tests for the lexer and token cursor, which further improves the core of Calva.
March 16-31
Debugger
I fixed some issues involving debugging and the REPL window. This required some modification of code involving the creation of the REPL window, and the handling of nrepl communication.
Terminating the REPL now ends the debug session, since it relies on the REPL.
I also improved the breakpoint-finding code, and this effort is still underway,as I found more cases I needed to account for, particularly around macro characters. I added some logic to our token cursor code to assist with this functionality, and wrote some tests to cover the added logic as well as extra tests to cover some existing logic.
Once the breakpoint-finding code has been improved at least to a satisfiable point, I’ll be writing tests for it to ensure that changes to the token cursor or other dependencies in the future will be accounted for and there will be less of a likelihood of debugger regressions.
Documentation will then be written to cover the existing functionality before an initial release is made.
Use of Babashka on the Horizon
Soon babashka will have an nrepl server, and with this generic connection enabled, Calva can be used with babashka scripts, much as it can be used with regular Clojure code.
Reagent
March 1-15
After reading the previous update, Roman Liutikov (roman01la) messaged me
and mentioned React.memo can be used to wrap functional components and
control when the render function is called. I implemented the same logic
Reagent used with shouldComponentUpdate using this method, and most of
the remaining test cases (where the difference was number of render calls)
were fixed.
After this change, and finally finding the problem with optimized builds and fixing them, I tested this version of Reagent with a work project, and didn’t find any obvious problems. To help with migration to new Reagent version, related to moving DOM related functions to separate namespace, I created Reagent 0.10.0 release. This version marks the functions deprecated, so library authors have some time to fix calls before functions are removed.
March 16-30
Related to the functional render feature, I implemented first version
of providing options to Reagent. This way existing applications can keep
using the old implementation and Class components, and allow users to choose
if they want to try functional components. Additionally a custom component
can be added, which can be used to control per form if Class or functional
component is created. The first version looks promising, but there are still
a few problems with this. The options have to be provided (at least) to all
render, as-element and reactify-element calls, so in some cases
this can be quite verbose. Probably it is possible to keep one global
variable in Reagent for the default options, and allow users to change that.
Another problem is that several of the caches Reagent uses, need to take
the options into account. I’m already testing solution where options are used
to build an object (“Compiler instance”), and this object can hold the caches.
These changes are also related to the second objective of Clojurist Together grant: “Configurable (Reagent-)hiccup compiler” and the first target is to use configuration for controlling if Class or functional components are created.
Other changes I’ve done during the previous two weeks, include improving the documentation and examples, and adding code coverage reporting to CI and Github.